 Puzzle Research Data Technology Searching, Creating and Giving the Best
Puzzle Research Data Technology Searching, Creating and Giving the Best
Related Articles

Data Mining
 Data Mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual. Patut diingat bahwa kata mining sendiri berarti usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar. Karena itu Data Mining sebenarnya memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent), machine learning, statistik dan database. Data mining adalah proses menerapkan metode ini untuk data dengan maksud untuk mengungkap pola-pola tersembunyi. Dengan arti lain Data mining adalah proses untuk penggalian pola-pola dari data. Data mining menjadi alat yang semakin penting untuk mengubah data tersebut menjadi informasi. Hal ini sering digunakan dalam berbagai praktek profil, seperti pemasaran, pengawasan, penipuan deteksi dan penemuan ilmiah.
Data Mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual. Patut diingat bahwa kata mining sendiri berarti usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar. Karena itu Data Mining sebenarnya memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent), machine learning, statistik dan database. Data mining adalah proses menerapkan metode ini untuk data dengan maksud untuk mengungkap pola-pola tersembunyi. Dengan arti lain Data mining adalah proses untuk penggalian pola-pola dari data. Data mining menjadi alat yang semakin penting untuk mengubah data tersebut menjadi informasi. Hal ini sering digunakan dalam berbagai praktek profil, seperti pemasaran, pengawasan, penipuan deteksi dan penemuan ilmiah.
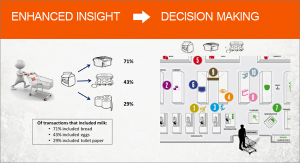
Data Science
Data Science merupakan ilmu atau teknik untuk mengeksplorasi dan mengekstrak sekumpulan data atau database sehingga dari sekumpulan data tersebut dapat ditemukan model, bentuk atau pola serta wawasan baru yang dapat digunakan sebagai salah satu alat untuk pengambilan keputusan. Banyak sekali manfaat serta fungsi dari data science ini diantaranya pada bidang bisnis untuk memprediksi produk apa yang akan laku dijual pada masa yang akan datang berdasarkan data transaksi penjualan, clusterisasi pangsa pasar untuk sebuah produk, menempatkan dua atau lebih produk yang berlainan atau market basket analysis dll, hasil atau output dari data science merupakan salah satu alat atau tools untuk pengambilan keputusan sehingga didapatkan nilai tambah dari sebuah bisnis.
Dari buku Practical Data Science with R di https://www.manning.com/books/practical-data-science-with-r bahwa dalam sebuah proyek data science melibatkan berbagai unsur yang salah satunya yang sangat vital adalah data scientist itu sendiri yang mempunyai fungsi dan tugas selain mengatur dan merencanakan design dari proyek itu supaya berhasil juga menentukan tools yang diperlukan serta melakukan test statistik dan memodelkan machine learning selanjutnya mengevaluasi hasil atau output dari proyek itu sendiri.
Untuk menjadi seorang data science atau sering disebut dengan data scientist kita harus mempunyai pengetahuan mengenai database, data scientist juga harus memahami algorithm dan machine learning diantaranya: Decision Tree, K-Means, Neural Network, Linear Regression, Logistic Regression, FP-Growth, Association Rules dll juga harus menguasai ilmu statistik serta memahami tools atau pemograman untuk statistik seperti SPSS, Stata, SAS, Pyhton ataupun R, dari ketiga tools atau bahasa pemograman tersebut cukup kita menguasai salah satunya saja misalkan menguasai bahasa pemograman R saja, terlepas dari kelebihan dan kekurangannya dengan R selain open source R juga merupakan bahasa pemograman yang dikhusukan untuk keperluan analysis statistik serta R juga dapat dihubungkan dengan Spark framework apabila kita akan mengeksplorasi Bigdata atau massive datasets.
Big Data
Big Data adalah data dengan ciri berukuran sangat besar, sangat variatif, sangat cepat pertumbuhannya dan mungkin tidak terstruktur yang perlu diolah khusus dengan teknologi inovatif sehingga mendapatkan informasi yang mendalam dan dapat membantu pengambilan keputusan yang lebih baik. Keempat karakterik tersebut: berukuran sangat besar (high-volume), atau sangat bervariasi (high-variety), atau kecepatan pertumbuhan tinggi (high-velocity), dan sangat tidak jelas (high veracity) sering disebut dengan 4V’s of Big Data.
Teknologi Big Data diciptakan untuk menangani keempat ciri di atas. Jadi jika data Anda memiliki satu ciri saja atau beberapa kombinasi ciri di atas, tentunya dapat memanfaatkan teknologi Big Data yang tersedia di pasaran. Definisi di atas merupakan kompilasi definisi dari Gartner – sebuah perusahaan riset dan konsultan IT yang sangat terkenal di dunia dan berbasis di US – dan beberapa organisasi lain yang menambahkan elemen high-veracity ke dalam definisi Gartner.
