 Puzzle Research Data Technology Searching, Creating and Giving the Best
Puzzle Research Data Technology Searching, Creating and Giving the Best
Related Articles

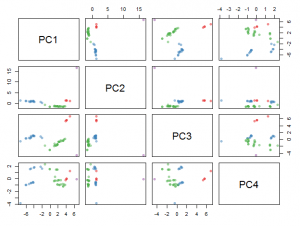 K-Means is a very popular algorithm for clustering, it is reliable in computation, simple and flexible. However, K-Means also has a weakness in the process of determining the initial centroid, the change in value causes the change in resulting cluster. Principal Component Analysis (PCA) Algorithm is a dimension reduction method which can solve the main problem in K-Means by applying PCA eigenvector of covariance matrix as the initial centroid value on K-Means. From the results of conducted experiments with a combination of 4, 5 and 6 of attributes and the number of clusters, Davies Bouldin Index (DBI), Silhouette Index (SI) and Dunn Index (DI) cluster validity of PCA K-Means are better than the usual K-Means. It is implemented by testing 1,737 and 100,000 data, the result is the patterns formed by PCA K-Means can lower the value of DBI constantly, but for SI and DI, the formed pattern is likely to change. This study concluded that the cluster validity used as reference for comparing the algorithms is DBI.
K-Means is a very popular algorithm for clustering, it is reliable in computation, simple and flexible. However, K-Means also has a weakness in the process of determining the initial centroid, the change in value causes the change in resulting cluster. Principal Component Analysis (PCA) Algorithm is a dimension reduction method which can solve the main problem in K-Means by applying PCA eigenvector of covariance matrix as the initial centroid value on K-Means. From the results of conducted experiments with a combination of 4, 5 and 6 of attributes and the number of clusters, Davies Bouldin Index (DBI), Silhouette Index (SI) and Dunn Index (DI) cluster validity of PCA K-Means are better than the usual K-Means. It is implemented by testing 1,737 and 100,000 data, the result is the patterns formed by PCA K-Means can lower the value of DBI constantly, but for SI and DI, the formed pattern is likely to change. This study concluded that the cluster validity used as reference for comparing the algorithms is DBI.
Keywords: Covariance, Davis Bouldin Index, K-Means, PCA K-Means, Principal Component Analysis.
Conclusion
From the results and analysis conducted and according to the objectives of this research, it can be concluded that between K-Means and PCA K-Means the comparison of the best cluster validity value is PCA K-Means, all the experiments conducted is by applying 4, 5 and 6 clusters and attributes, PCA K-Means has the advantage on every experiment. In the case of using generated data random of 100,000 data, the result of DBI value is 0.5343 with SI value is 0.6264 and DI value is 0.5689. So it can be inferred that the more datasets used, then PCA K-Means is capable on lowering the value of DBI. However, regarding to SI and DI values, they do not have a specific pattern on the experimental result for both data small and large, no matter how much clusters and attributes is used. Therefore, PCA K-Means is an optimal algorithm for above cases, if the validity of the cluster used is DBI.
Mustakim
